A few weeks ago, I gave a quick overview of our entire technology stack here at Commission Junction and now it's time to dig deeper into how we really work. The above image is our current deployment pipeline dashboard, and this week I'd like to start describing our Continuous Delivery/Continuous Deploy [CD] process: the process that we use to get our software to our customers.
On a high level, we wanted a single automated process that would take each change that a developer made to the existing code base and subject that change to a pipeline of increasing challenges all the way up to "deployment." Since we're a public company that deals with our customer's money, we differentiate Deployment from Release; that is, we deploy to a preproduction staging environment that is identical to production that can be viewed by select customers and internal folks, but isn't "out in production yet." We then "Release" code from the pre-production environment, but we use the identical tooling to do both deployment and releasing.
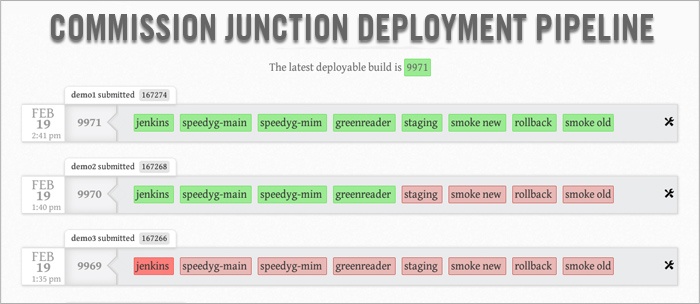
The Pipeline Dashboard above, shows three rows, where each row represents a new build from a new set of changes. The row which is fully green, in the pipeline above has passed each stage [each box represents a stage in the build and is a specific challenge to the payload]. In subsequent rows, parts of the pipeline have not succeeded [those failed stages are shown in red] which means the build fails.
Speed is critical for us. We wanted to be able to answer the question that each developer asks the CD support system. As a developer, if I make a change to the existing code, how fast can I get a response back from the automated pipeline that will tell me whether I 'broke the deployment?' We keep the main branch as 'green as possible' and always 'deployable.' We want very rapid feedback, but there isn't all that much off-the-shelf tooling out there, so we elected to build the parts that weren't available in-house.
The overarching principle is this: we want to have modifications to our code as tested as possible, and have the testing and deploying pipeline subject those modifications completely so the code is "done." We call this set of changes, a "payload candidate." "Done" means that our developers have completed everything that they can think to do, from the payload candidate to creating finished software: building, full automated testing [at each of unit, component, functional, and end-to-end level], automated db scripting, automated environment configuration testing, smoke testing, and finally the testing of the deployment steps, including any possible rollback of the payload candidate.
Each "stage" in our CD pipeline represents a new challenge for a new modification to our existing code base. If a payload candidate for production makes it all the way through the pipeline, we deem it ready for deployment.
In the coming weeks, we will discuss each stage in further detail.
Advertiser/Agency
You sell or promote products and services and work with websites and creators, paying commissions for sales, leads or traffic.
Publisher/Creator
You've built an audience or following and want to earn commissions by promoting brands and products you believe in.
Share